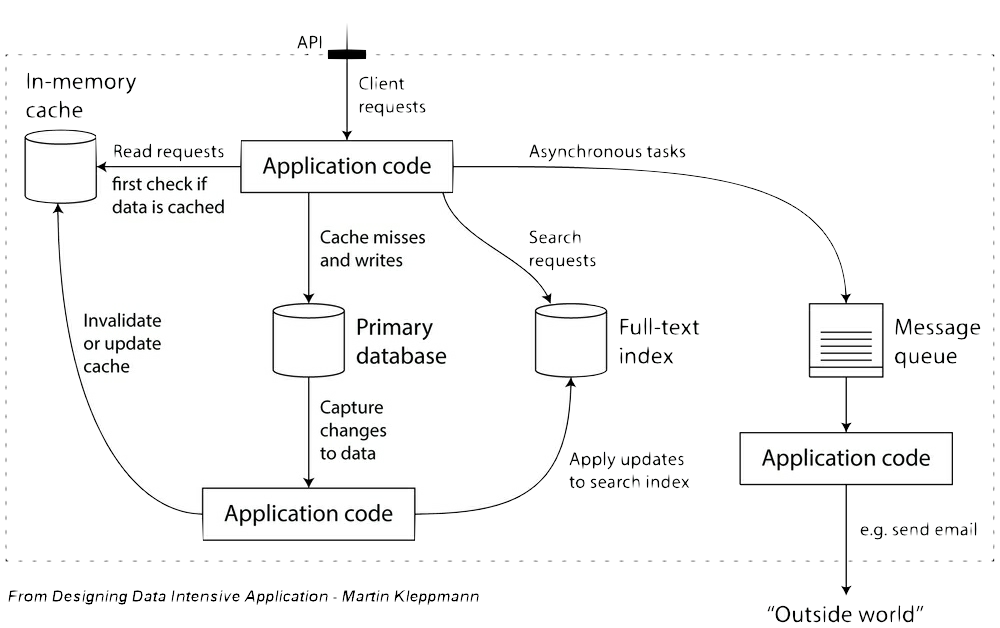
About
The View Selection Problem (VSP) is an NP-Complete problem.
Challenges:
- Design Which materializations to create?
- Populate Load them with data
- Maintain Incrementally populate when data changes
- Rewrite Transparently rewrite queries to use materializations
- Adapt Design and populate new materializations, drop unused ones
- Express Need a rich algebra, to model how data is derived
OLAP technics are powerful tools to answer analytical queries in data warehouses. OLAP represents data in a multidimensional cube and usually supports a multidimensional query language (either as a real query language such as MDX or as a visual query interface).
A typical implementation variant is ROLAP where the cube is mapped to a set of base tables in a relational DBMS modeled as star or snowake schema.
Hence, a multidimensional OLAP query has to be translated into one or a sequence of SQL queries following the star join pattern and usually containing complex grouping and aggregation operations.
In order to speed up query processing so-called aggregation tables are used. These tables are (partial) materializations of query results. To decide which results to materialize the cost-bene fit tradeoff has to be taken into account.
Aggregation tables improve query response time but require additional disk space and maintenance costs. The problem of identifying the optimal set of aggregation tables is called the view selection problem and due to the large number of possible aggregations known to be NP complete.
Nowadays, commercial DBMS support aggregation tables in the form of materialized views
They provide sophisticated techniques for query rewriting, incremental maintenance, and ( usually implemented as an external administration tool ) recommending aggregation tables :
However, particularly the latter step is still a static solution that has to be carried out manually and repeated after changes in the data or the workload. Unfortunately, determining the optimum set of aggregation tables given limited space is a hard problem and a very expensive process. Thus, such an algorithm should be run as rarely as possible.