
Natural Language - N-gram language model
About
The N-gram language model is the most widely used language modeling approach. An N-gram is usually written as an N-word phrase, with the first N-1 words as the history, and the last word predicted as a probability based on the N-1 previous words.
Articles Related
Example
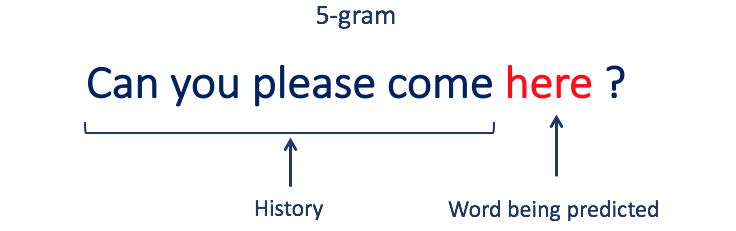
For example, “Can you please come here” contains 5 words and is a 5-gram. Its history is “Can you please come.” Based on that history, an N-gram language model can compute a conditional probability of the word “here.”
Large-scale, higher-order N-gram language models (e.g., N=5) have proven very effective in many applications, such as automatic speech recognition and machine translation. At Facebook, for example, this is used to automatically generate captions for videos uploaded to pages, and detecting pages with potentially low quality place names (eg. “Home sweet home,” “Apt #00, Fake lane, Foo City”).
Language models trained with large datasets have better accuracy compared with ones trained with smaller datasets. The possibility of covering ample instances of infrequent words (or N-grams) increases with a larger dataset. For training with larger dataset, distributed computing frameworks (e.g. MapReduce) are generally used for better scalability and parallelizing model training.