About
(Stream|Pipe|Message Queue|Event Processing) in Kafka.
The stream API
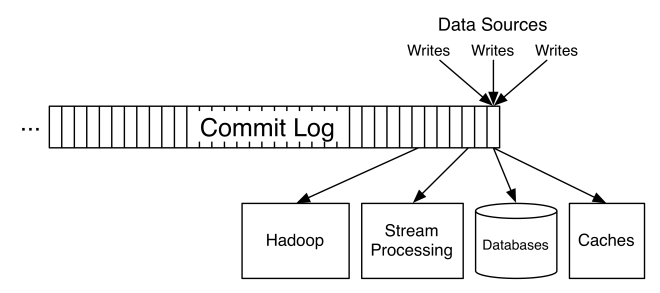
The Kafka cluster stores streams of records in categories called topics.
Articles Related
Management
Configuration
Application Id
Application Id (application.id): Each stream processing application must have a unique id.
This id is used in the following places to isolate resources used by the application from others:
- As the default Kafka consumer and producer client.id prefix
- As the Kafka consumer group.id for coordination
- As the name of the sub-directory in the state directory (cf. state.dir the directory location for state stores)
- As the prefix of internal Kafka topic names
Update
When an application is updated, it is recommended to change application.id unless it is safe to let the updated application re-use the existing data in internal topics and state stores. One pattern could be to embed version information within application.id, e.g., my-app-v1.0.0 vs. my-app-v1.0.2.
Concept
https://docs.confluent.io/3.0.0/streams/concepts.html#streams-concepts
- A stream processor is a node in the processor topology that represents a single processing step.
- A stream is an unbounded, continuously updating data set.
API
Two:
- A high-level Kafka Streams DSL that provides common data transformation operations in a functional programming style such as map and filter operations.
- A low-level Processor API that lets you add and connect processors as well as interact directly with state stores.
Jar
| Group Id | Artifact Id | Description / why needed |
|---|---|---|
| org.apache.kafka | kafka-streams | Base library for Kafka Streams. Required. |
| org.apache.kafka | kafka-clients | Kafka client library. Contains built-in serializers/deserializers. Required. |
| org.apache.avro | avro | Apache Avro library. Optional (needed only when using Avro). |
| io.confluent | kafka-avro-serializer | Confluent’s Avro serializer/deserializer. Optional (needed only when using Avro). |
Code / Demo
- Code examples that demonstrate how to implement real-time processing applications using Kafka Streams. See readme.