About
Data Partitions (Clustering of data) in Kafka
Each partition is an:
- ordered,
- immutable sequence of records
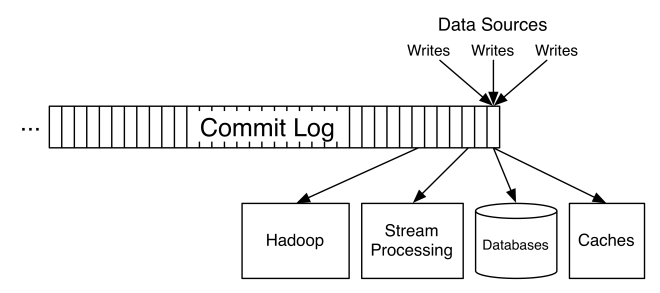
that is continually appended to—a structured commit log.
The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
Each partition in the Kafka cluster has:
- a leader
Articles Related
Purpose
Partitions:
- act as the unit of parallelism
* 1 Partition = 1 process
* 2 partition = 2 process
* ...
Structure
Topic
* -> partition 1
* -> segment 11
* -> segment 12
* -> partition 2
* -> segment 21
* -> segment 22
.......
where:
Physic Server Distribution
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions.
Record Partition Assignment
The producer is responsible for choosing which record to assign to which partition within the topic. See Kafka - Producer (Write / Input)
Replication
Each partition is replicated across a configurable number of servers for fault tolerance.
Replicated partitions are called replicas
Leader / Follower
The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader.
Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Each partition has one server which acts as the leader and zero or more servers which act as followers.
Rebalance
If you're running out of capacity, you will add more brokers to your cluster, and then rebalance the partitions in your cluster to move the load around.
You can do it using
- the kafka-reassign-partitions script,
- Confluent Auto Data Balancer