Kafka (Event Hub)
About
Apache Kafka is a broker application that stores the message as a distributed commit log.
The entire data storage system is just a transaction log.
LinkedIn created Apache Kafka to be the data exchange backbone of its organization. Linkedin Motivation: A unified platform for handling all the real-time |data feeds a large company might have.
The data dichotomy:
Apache Kafka is a distributed system designed for streams.
- a messaging system
- storing the producer data in a structured commit log of updates (up to many TBs of data)
- where each data consumers consume this stream in order, tracking its own position in the Kafka log and advances independently.
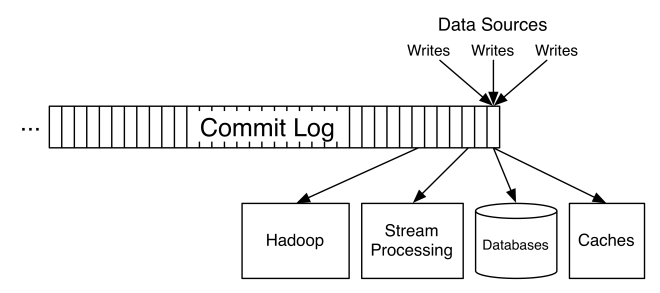
The Kafka log can be sharded and spread over a cluster of machines, and each shard is replicated for fault-tolerance. (Allowing parallelism, ordered consumption)
The log is the first data structure and tables are derived views and stored in RocksDB. Updates to these tables can be modeled as streams
Concept
- Kafka is run as a cluster on one or more servers.
Architecture
- Kafka’s connect API = E and L in Streaming ETL
- Kafka’s streams API = The T in STREAMING ETL, Easiest way to do stream processing using Kafka
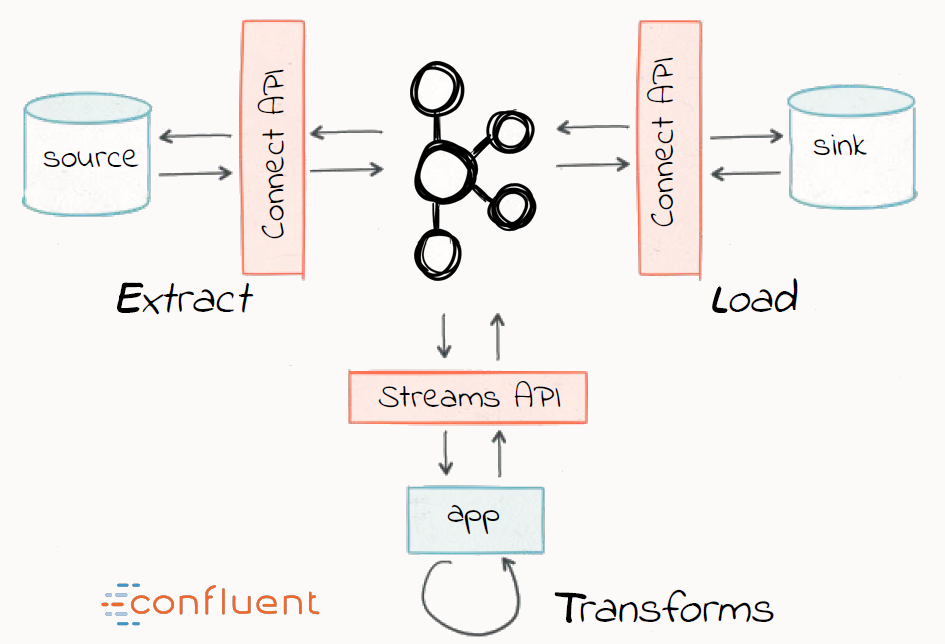
Application
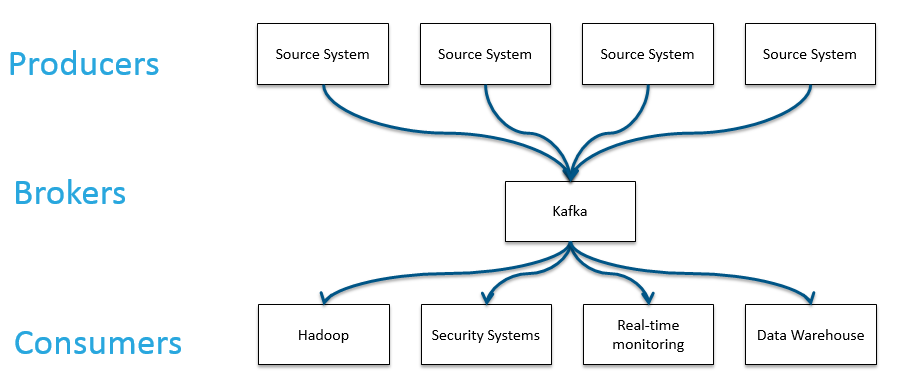
Kafka can serve as a buffer for data:
- during high machine load.
- during high waiting such as unreliable connections (to send data to offshore data centers)
Event thinking:
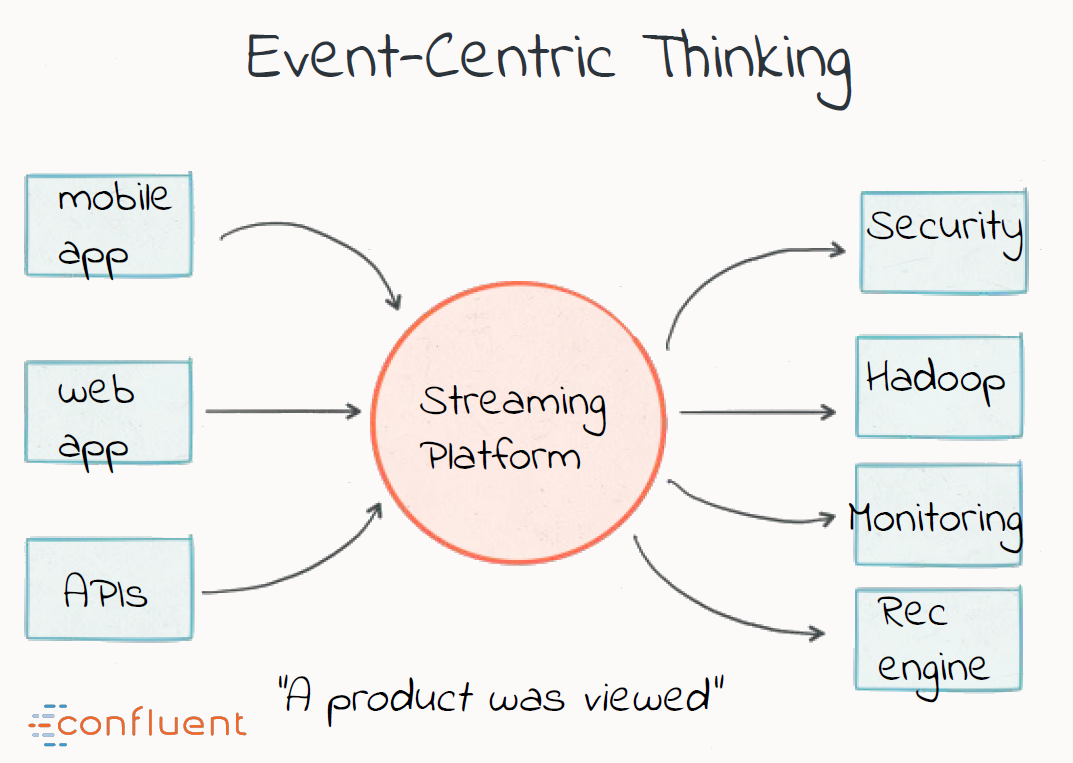
leads to this architecture:
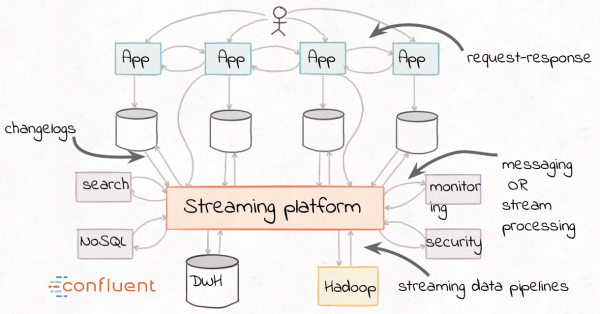
forward-compatible data architecture the ability to add more applications that need to process the same data … differently
Features
- Can keep data forever
- Scales very well – high throughputs, low latency, lots of storage
- Scales to any number of consumers
Advantage
- If a bug arise, you can suppress and rerun the whole process. The workflow is restartable and therefore resilient
See also Kafka on Google because …
Usage
- As a message bus
- As a buffer for replication systems (Like AdvancedQueue in Streams)
- As reliable feed for event processing
- As a buffer for event processing
- Decouple apps from database (both OLTP and DWH)
Schema
Kafka only stores Bytes – So where’s the schema?
- In an utility (code) for reading/writing messages that everyone reuses
- Schema embedded in the message
- A centralized repository for schemas (Each message has Schema ID, Each topic has Schema ID)
See talk: Gwen Shapira discusses patterns of schema design, schema storage and schema evolution that help development teams build better contracts through better collaboration - and deliver resilient applications faster. Streaming Microservices: Contracts & Compatibility
Monitoring
Tools
Blog
Dev
Actual vs history
To reduce the load time issue it’s useful to keep a snapshot of the event log using a compacted topic. It represents the ‘latest’ set of events, without any of the ‘version history’.
hold events twice: once in a retention-based topic and once in a compacted topic. The retention-based topic will be larger as it holds the ‘version history’ of your data. The compacted topic is just the ‘latest’ view, and will be smaller, so it’s faster to load into a Memory Image or State Store.
Latency
load one million products into memory, at say 100B each. This would take around 100MB of RAM and would load from Kafka in around a second on GbE. These days memory is typically easier to scale than network bandwidth so ‘worst case load time’ is often the more limiting factor of the two.
Documentation / Reference
AWS
Architecture
Documentation
Edition Comparison
ETL
- ETL is dead, long live streams Blog, Talk and Slides
Code / Sample
- https://github.com/confluentinc/examples/tree/3.3.0-post/kafka-connect-streams - various ways, with and without Kafka Connect, to get data into Kafka topics and then loaded into the Kafka Streams API KStream - Show some basic usage of the stream processing API
- This demo shows users how to monitor Kafka streaming ETL deployments using Confluent Control Center. The use case is a streaming pipeline built around live edits to real Wikipedia pages. Wikimedia Foundation has IRC channels that publish edits happening to real wiki pages (e.g. #en.wikipedia, #en.wiktionary) in real time.
- https://github.com/kaiwaehner/kafka-streams-machine-learning-examples - examples which demonstrate how to deploy analytic models to mission-critical, scalable production leveraging Apache Kafka and its Streams API.