
About
TPC - DS in Spark.
Articles Related
Management
Package
cd d:\spark-sql-perf
sbt package
[info] Loading project definition from D:\tmp\spark-sql-perf\project
[info] Updating {file:/D:/tmp/spark-sql-perf/project/}spark-sql-perf-build...
[info] Resolving org.fusesource.jansi#jansi;1.4 ...
[info] Done updating.
Missing bintray credentials C:\Users\gerard\.bintray\.credentials. Some bintray features depend on this.
[info] Set current project to spark-sql-perf (in build file:/D:/tmp/spark-sql-perf/)
[warn] Credentials file C:\Users\gerard\.bintray\.credentials does not exist
[info] Updating {file:/D:/tmp/spark-sql-perf/}spark-sql-perf...
[info] Resolving jline#jline;2.12.1 ...
[info] Done updating.
[warn] Multiple main classes detected. Run 'show discoveredMainClasses' to see the list
[info] Packaging D:\tmp\spark-sql-perf\target\scala-2.11\spark-sql-perf_2.11-0.5.0-SNAPSHOT.jar ...
[info] Done packaging.
[success] Total time: 7 s, completed Jul 10, 2018 3:38:23 PM
Jar goes to spark-sql-perf\target\scala-2.11\spark-sql-perf_2.11-0.5.0-SNAPSHOT.jar
dsgen
spark-sql-perf\src\main\scala\com\databricks\spark\sql\perf\tpcds\TPCDSTables.scala#DSDGEN
- RNGSEED is the RNG seed used by the data generator and is fixed to 100.
dsdgen -table $name -filter Y -scale $scaleFactor -RNGSEED 100 -parallel $partitions -child $i
Run
bin/run --benchmark DatasetPerformance
# Will run
# java -Xms2048m -Xmx2048m -XX:MaxPermSize=512m -XX:ReservedCodeCacheSize=256m -jar build/sbt-launch-0.13.18.jar runBenchmark
- Output:
[info] Running com.databricks.spark.sql.perf.RunBenchmark --benchmark DatasetPerformance
[error] Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
....
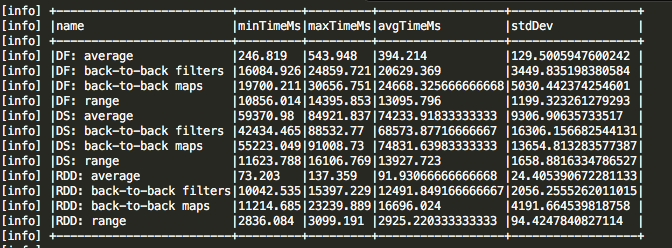
The DatasetPerformance is the default test suite/test case or benchmark class and once you are able to compile and run this, you shoud see static output.
Others
https://github.com/databricks/spark-sql-perf/blob/master/src/main/notebooks/tpcds_datagen.scala
bin/run –benchmark DatasetPerformance ?
This is the default test suite/test case or benchmark class and once you are able to compile and run this, you will see static output.
Post: https://galvinyang.github.io/2016/07/09/spark-sql-perf%20test/
build spark with -Phive profile to add Hive as a dependency. Then you can use HiveContext that has a parser with better SQL coverage and metastore support. For the method of createExternalTable, it uses Hive metastore to persist metadata (you can just use the built-in derby metastore).
Make sure you create a jar of spark-sql-perf (using sbt) . When starting spark-shell use the command –jars and point it to that jar. e.g., ./bin/spark-shell –jars /Users/xxx/yyy/zzz/spark-sql-perf/target/scala-2.11/spark-sql-perf_2.11-0.5.0-SNAPSHOT.jar
tpcds - installation hack
import os
import subprocess
import time
import socket
# IMPORTANT: UPDATE THIS TO THE NUMBER OF WORKER INSTANCES ON THE CLUSTER YOU RUN!!!
num_workers=3
# Install a modified version of dsdgen on the cluster.
def install(x):
p = '/tmp/install.sh'
if (os.path.exists('/tmp/tpcds-kit/tools/dsdgen')):
time.sleep(1)
return "", ""
with open(p, 'w') as f:
f.write("""#!/bin/bash
sudo apt-get update
sudo apt-get -y --force-yes install gcc make flex bison byacc git
cd /tmp/
git clone https://github.com/databricks/tpcds-kit.git
cd tpcds-kit/tools/
make -f Makefile.suite
/tmp/tpcds-kit/tools/dsdgen -h
""")
os.chmod(p, 555)
p = subprocess.Popen([p], stdin=None, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out, err = p.communicate()
return socket.gethostname(), out, err
sc.range(0, num_workers, 1, num_workers).map(install).collect()