HomeDbSparkEnginePartition
Table of Contents
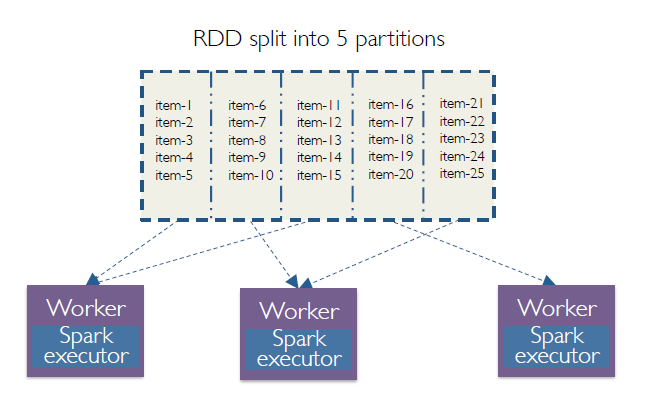
Data Partitions (Clustering of data) in Spark
5 partitions and 3 executors