
About
To build an histogram (graphic) from data, see Oracle Database - Histogram Analytic
Data Dictionary Column statistics may be stored as histograms. These histograms provide accurate estimates of the distribution of column data. Histograms provide improved selectivity estimates in the presence of data skew, resulting in optimal execution plans with non-uniform data distributions.
Articles Related
Example
For example, for an equality predicate (last_name = 'Smith'), selectivity is set to the reciprocal of the number n of distinct values of last_name, because the query selects rows that all contain one out of n distinct values. If a histogram is available on the last_name column, then the estimator uses it instead of the number of distinct values. The histogram captures the distribution of different values in a column, so it yields better selectivity estimates. Having histograms on columns that contain skewed data (in other words, values with large variations in number of duplicates) greatly helps the query optimizer generate good selectivity estimates.
Type
Oracle uses the following types of histograms for column statistics:
The type of histogram is stored in the HISTOGRAM column of the *TAB_COL_STATISTICS views (USER and DBA). This column can have values of :
- HEIGHT BALANCED,
- FREQUENCY,
- or NONE.
Frequency histograms are automatically created instead of height-balanced histograms when the number of distinct values is less than or equal to the number of histogram buckets specified.
Height-Balanced Histograms
In a height-balanced histogram, the column values are divided into bands so that each band contains approximately the same number of rows. The useful information that the histogram provides is where in the range of values the endpoints fall.
Consider a column C with values between 1 and 100 and a histogram with 10 buckets. If the data in C is uniformly distributed, then the histogram looks similar to this one, where the numbers are the endpoint values.
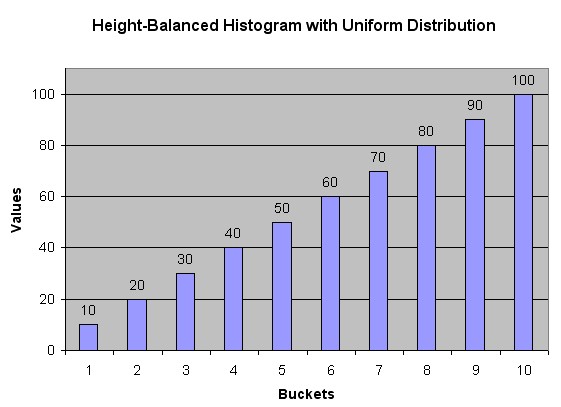
The number of rows in each bucket is one tenth the total number of rows in the table. Four-tenths of the rows have values that are between 60 and 100 in this example of uniform distribution.
If the data is not uniformly distributed, then the histogram might look similar to :.
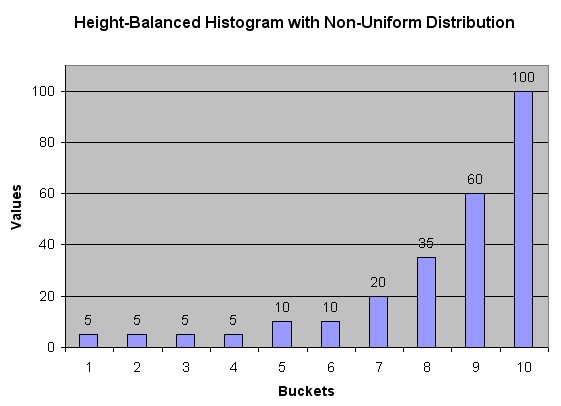
In this case, most of the rows have the value 5 for the column. Only 1/10 of the rows have values between 60 and 100.
Example
Height-balanced histograms with number
Height-balanced histograms can be viewed using the TAB_HISTOGRAMS tables.
oe@orcl>BEGIN
2 DBMS_STATS.GATHER_table_STATS (OWNNAME => 'OE', TABNAME => 'INVENTORIES',
3 METHOD_OPT => 'FOR COLUMNS SIZE 10 quantity_on_hand');
4 END;
5 /
PL/SQL procedure successfully completed.
oe@orcl>SELECT column_name, num_distinct, num_buckets, histogram
2 FROM USER_TAB_COL_STATISTICS
3 WHERE table_name = 'INVENTORIES' AND column_name = 'QUANTITY_ON_HAND';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
============================== ============ =========== ===============
QUANTITY_ON_HAND 237 10 HEIGHT BALANCED
oe@orcl>SELECT endpoint_number, endpoint_value
2 FROM USER_HISTOGRAMS
3 WHERE table_name = 'INVENTORIES' and column_name = 'QUANTITY_ON_HAND'
4 ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE
=============== ==============
0 0
1 27
2 41
3 57
4 74
5 98
6 122
7 149
8 175
9 202
10 353
11 rows selected.
In the query output, one row corresponds to one bucket in the histogram.
Height-balanced histograms with string
To generate a height balanced histogram for a string column, Oracle take the first 15 characters and convert it in a number. It's the very difficult to reverse it. You can see however an example of this function in this script char_value.zip from Lewis. The endpoint string value is stored in the endpoint_actual_value column. You can see in the next example that the DBMS_STATS package don't gathered this column while the good old analytic function does.
Why this difference ? According to Tom :
- dbms_stats is the thing that the optimizer expects to have generated the statistics.
- dbms_stats is what is tested with the optimizer, analyze is not.
- dbms_stats and analyze have always returned different results.
oe@orcl>BEGIN
2 DBMS_STATS.GATHER_table_STATS (OWNNAME => 'OE', TABNAME => 'CUSTOMERS',
3 METHOD_OPT => 'FOR COLUMNS SIZE 10 CUST_LAST_NAME');
4 END;
5 /
PL/SQL procedure successfully completed.
oe@orcl>SELECT column_name, num_distinct, num_buckets, histogram
2 FROM USER_TAB_COL_STATISTICS
3 WHERE table_name = 'CUSTOMERS' AND column_name = 'CUST_LAST_NAME';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
============================== ============ =========== ===============
CUST_LAST_NAME 176 10 HEIGHT BALANCED
oe@orcl>SELECT endpoint_number, endpoint_value, endpoint_actual_value
2 FROM USER_HISTOGRAMS
3 WHERE table_name = 'CUSTOMERS'
4 AND column_name = 'CUST_LAST_NAME'
5 ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE ENDPOINT_A
=============== ============== ==========
0 3.3954E+35
1 3.4501E+35
2 3.5027E+35
3 3.6544E+35
4 3.7582E+35
5 3.9140E+35
6 4.0178E+35
7 4.1744E+35
8 4.3298E+35
9 4.3334E+35
10 6.1495E+35
11 rows selected.
oe@orcl>analyze table CUSTOMERS compute statistics for columns CUST_LAST_NAME size 10;
Table analyzed.
oe@orcl>SELECT endpoint_number, endpoint_value, endpoint_actual_value
2 FROM USER_HISTOGRAMS
3 WHERE table_name = 'CUSTOMERS'
4 AND column_name = 'CUST_LAST_NAME'
5 ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE ENDPOINT_A
=============== ============== ==========
0 3.3954E+35 Adjani
1 3.4501E+35 Bradford
2 3.5027E+35 Curtis
3 3.6544E+35 Fawcett
4 3.7582E+35 Harris
5 3.9140E+35 Kazan
6 4.0178E+35 Mason
7 4.1744E+35 Peckinpah
8 4.3298E+35 Schneider
9 4.3334E+35 Sutherland
10 6.1495E+35 von Sydow
11 rows selected.
Little histograms SQL without buckets
SELECT CUST_LAST_NAME AS "Department",
LPAD('+', COUNT(*), '+') as Histogram, count(*) as Value
FROM customers
GROUP BY CUST_LAST_NAME
order by value
Frequency Histograms
In a frequency histogram, each value of the column corresponds to a single bucket of the histogram. Each bucket contains the number of occurrences of that single value.
Frequency histograms are automatically created instead of height-balanced histograms when the number of distinct values is less than or equal to the number of histogram buckets specified.
Frequency histograms can be viewed using the TAB_HISTOGRAMS views.
BEGIN
DBMS_STATS.GATHER_table_STATS (OWNNAME => 'OE', TABNAME => 'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 20 warehouse_id');
END;
/
SELECT column_name, num_distinct, num_buckets, histogram
FROM USER_TAB_COL_STATISTICS
WHERE table_name = 'INVENTORIES'
AND column_name = 'WAREHOUSE_ID';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------------------------ ------------ ----------- ---------------
WAREHOUSE_ID 9 9 FREQUENCY
SELECT endpoint_number, endpoint_value
FROM USER_HISTOGRAMS
WHERE table_name = 'INVENTORIES'
AND column_name = 'WAREHOUSE_ID'
ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
36 1
213 2
261 3
370 4
484 5
692 6
798 7
984 8
1112 9