The fundamental difference and advantage of Oracle's capabilities, however, is that parallel data access and therefore the necessary data redistribution are not constrained by any given hardware architecture or database setup.
Operations That Can Be Parallelized
The Oracle server can use parallel execution for any of the following:
- Access methods. For example, table scans, index full scans, and partitioned index range scans.
- DDL statements. CREATE TABLE AS SELECT, CREATE INDEX, REBUILD INDEX, REBUILD INDEX PARTITION, and MOVE SPLIT COALESCE PARTITION
- DML statements. For example, INSERT AS SELECT, updates, deletes, and MERGE operations.
- Miscellaneous SQL operations. For example, GROUP BY, NOT IN, SELECT DISTINCT, UNION, UNION ALL, CUBE, and ROLLUP, as well as aggregate and table functions.
Principle
OLTP and DataWarehouse
- DataWarehouses: A DataWarehouse should always use parallel execution to achieve good performance.
- OLTP: Specific operations in OLTP applications, such as batch operations, can also significantly benefit from parallel execution.
The ultimate goal: scalability
If you allocate twice the number of resources and achieve a processing time that is half of what it was with the original amount of resources, then the operation scales linearly.
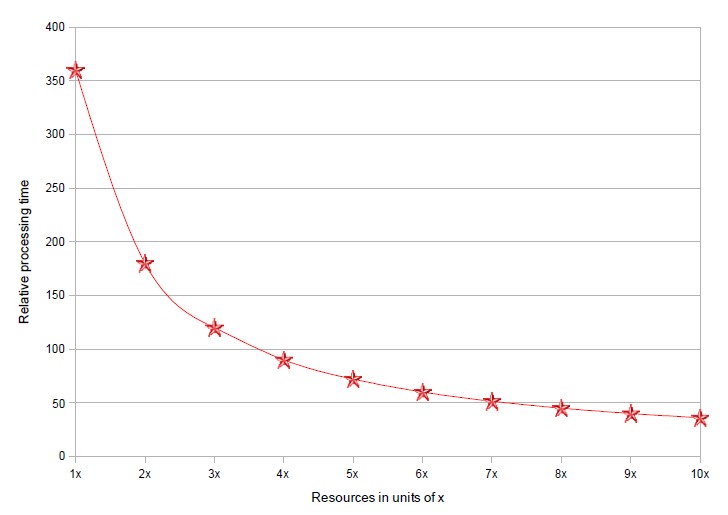
The graph does not look linear because it shows the absolute processing time, not a relative speedup factor.
For example, using 2x the resources reduces the processing time from 360 to 180, and from 2x to 4x down to 90, both cases of linear scalability. It's just that the absolute performance gain is decreasing with higher number of resources.
When you spend two thirds of the original processing time to complete the task. When doubling the resources does not give the expected linear reduction in processing time, the operation does not scale as well.
In a database there are multiple components involved in processing a query, each having its own maximum processing power. Most notably CPUs, memory and Input/Output (I/O) all collaborate together.
For database processing you may experience a lack of scalability if you don't allocate resources in the correct quantities across the various components. For example, if you add CPU resources but you don't add I/O resources then the CPUs may not be able to retrieve the data fast enough to keep processing at full speed.
Examples of resource-intensive database operations
Examples of resource-intensive database operations include:
- Large (long-running) queries: for example data warehouse analysis comparing one year's results with the results of the year prior
- Building indexes on large tables (Index builds)
- Gathering statistics in a large database
- Loading a large amount of data into a database
- Taking a database backup (RMAN backups)
- SQL loader and SQL-based data loads
- And more