(Apache) Hadoop
About
Apache Hadoop is basically 3 things:
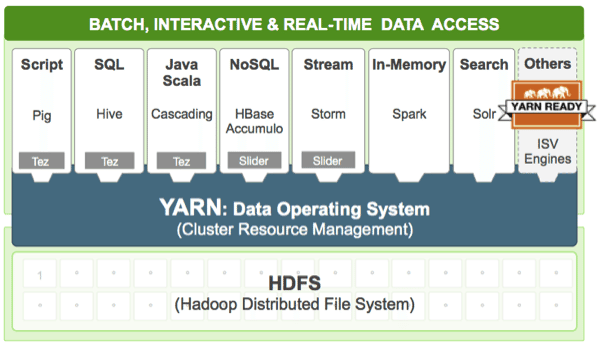 Image comes from Hortonworks
Image comes from Hortonworks
Hadoop:
- scales, runs on commodity hardware where you setup a Hadoop cluster (a group of machines connected together over a network)
- is fault tolerant.
- is good for “embarassingly parallel” problems, such as building an index for the web.
Steps:
- setting up a Hadoop cluster and then store huge amounts of data spread across all the machines into the HDFS
- processing the scattered data by writing MapReduce programs (or jobs) that goes locally on each machine in order to not relocate the data.
Single threaded writes.
Use cases
- Data Warehouse/Analytics Offload
- Data Lake/Enterprise Data Hub
Building
The BUILDING.txt in the code repository has all information to build it (also for windows)
Proposition
Oracle: Big Data Appliance
In Oct 2011, Oracle announced the Big Data Appliance, which integrates:
- Cloudera's Distribution Including Hadoop (CDH),
- Oracle Enterprise Linux,
- the R programming language,
- and a NoSQL database
with the Exadata hardware.