About
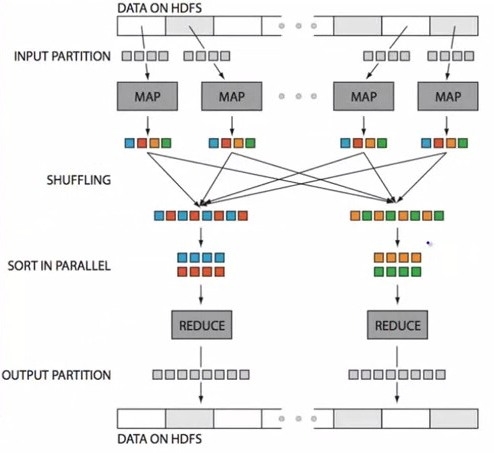
Distributed SQL query processing in Hadoop differs from conventional relational query engine when it comes to handling of intermediate result sets. Query processing often requires sorting and reassembling of intermediate result set; this is called shuffling in Hadoop parlance.
Most of the existing query optimizations in Hive are about minimizing shuffling cost.
Articles Related