About
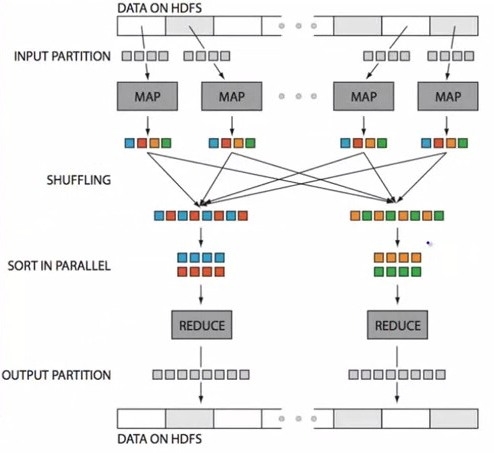
Partitioner partitions the key space from the map-outputs to be sent to the reducer.
The total number of partitions is the same as the number of reduce tasks for the job
It controls which of the m reduce tasks the intermediate key (and hence the record) is sent to for reduction.
Articles Related
Implementation
The key (or a subset of the key) is used to derive the partition, typically by a hash function. See default
Management
Default
HashPartitioner is the default Partitioner.