About
The Map implementation in Hadoop in a application
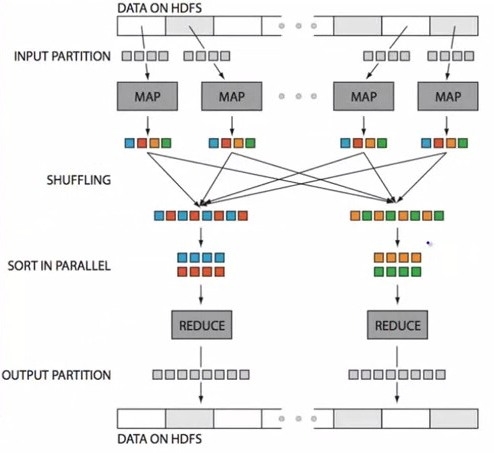
Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records.
Articles Related
Implementation
- Mapper implementations are passed to the job via Job.setMapperClass(Class) method.
- The framework then calls map(WritableComparable, Writable, Context) for each key/value pair in the InputSplit
Applications implements this map function and:
- collect Output pairs with calls to context.write(WritableComparable, Writable).
- can override the cleanup(Context) method to perform any required cleanup.
- can use the Counter to report its statistics.
- can control the grouping by specifying a Comparator via Job.setGroupingComparatorClass(Class))
- can specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data transferred from the Mapper to the Reducer.
- can control the compression via the Configuration.
- can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
The Mapper outputs are:
- sorted
- stored in a simple (key-len, key, value-len, value) format.
- passed to the Reducer.
Management
Number
The Hadoop MapReduce framework spawns one map task for each InputSplit generated by the InputFormat for the job.
The number of maps is usually driven by the total size of the inputs, that is, the total number of blocks of the input files.
Example:
- 10TB of input data
- a blocksize of 128MB
<MATH> \text{number of map} = \frac{10 * 1024 * 1024}{128} = 81 920 </MATH>
The total number of map can be set to be higher with Configuration.set(MRJobConfig.NUM_MAPS, int) (This provides just a hint).
- The right level of parallelism for maps seems to be around 10-100 maps per-node
- It is best if the maps take at least a minute to execute.