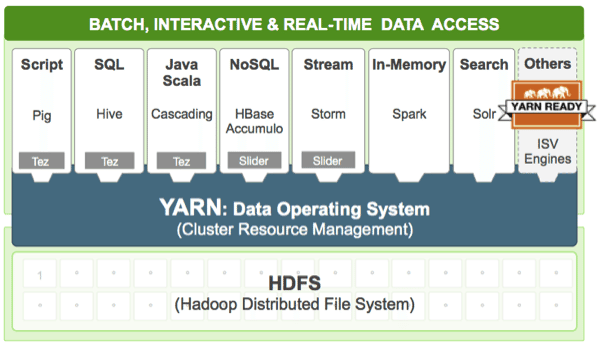
About
NameNode is an HDFS daemon that run on the head node.
It' s the head process of the cluster that manages:
- the file system namespace
- and regulates access to files by clients.
The NameNode:
- executes file system namespace operations like opening, closing, and renaming files and directories.
- determines the mapping of blocks to DataNodes
The NameNode is the arbitrator and repository for all HDFS metadata.
The NameNode makes all decisions regarding replication of blocks.
It periodically receives from each of the DataNodes in the cluster:
- a Heartbeat (to see if the node is alive)
- and a Blockreport (the list of all blocks)
The NameNode manages the file system metadata. See HDFS - File System Metadata
The NameNode constantly tracks which blocks need to be replicated and initiates replication whenever necessary.
Articles Related
Management
UI
A browser admin client is available at
http://nn_host:port/
where:
- Default HTTP port is 50070.
Cli
hdfs namenode --help
Usage: java NameNode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-upgradeOnly [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-rollback] |
[-rollingUpgrade <rollback|downgrade|started> ] |
[-finalize] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby] |
[-recover [ -force] ] |
[-metadataVersion ]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
PID
NNPID=$("$JAVA_HOME"/bin/jps | grep -E '^[0-9]+[ ]+NameNode$' | awk '{print $1}')
# secondary namenode
SNNPID=$("$JAVA_HOME"/bin/jps | grep -E '^[0-9]+[ ]+SecondaryNameNode$' | awk '{print $1}')
Safemode
On startup, the NameNode enters a special state called Safemode. Replication of data blocks does not occur when the NameNode is in the Safemode state.
The NameNode receives Heartbeat and Blockreport messages from the DataNodes. After a configurable percentage of safely replicated data blocks checks in with the NameNode (plus an additional 30 seconds), the NameNode exits the Safemode state. It then determines the list of data blocks (if any) that still have fewer than the specified number of replicas. The NameNode then replicates these blocks to other DataNodes.
Refresh
See the options refreshNamenodes of dfsadmin
For the given datanode:
- reloads the configuration files,
- stops serving the removed block-pools
- and starts serving new block-pools
List
- gets list of namenodes in the cluster.
hdfs getconf -namenodes
- gets list of secondaryNameNode in the cluster.
hdfs getconf -secondaryNameNodes
rpc adresses
- gets the namenode rpc addresses
hdfs getconf -nnRpcAddresses
Start
- If in high availability: HDFS - JournalNode (JN)
# $HDFS_USER is the HDFS user. normally hdfs.
su -l $HDFS_USER -c "/usr/hdp/current/hadoop-hdfs-journalnode/../hadoop/sbin/hadoop-daemon.sh start journalnode"
- then
# $HDFS_USER is the HDFS user. normally hdfs.
su -l $HDFS_USER -c "/usr/hdp/current/hadoop-hdfs-namenode/../hadoop/sbin/hadoop-daemon.sh start namenode"
Class
CLASS='org.apache.hadoop.hdfs.server.namenode.NameNode'
CLASS='org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode'
Log
/var/log/hadoop/hdfs/