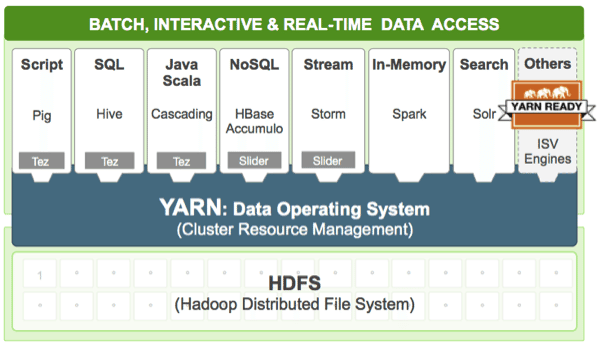
About
An edge node is a node with the same client tools installed and configured as in the headnodes, but with no Hadoop services running.
An edge node is a separate machine that isn’t used to store data or perform computation.
Articles Related
Usage
Prevent cluster crash
Many organizations submit jobs from the edge node. Since the edge node is separate from the cluster, it can go down without affecting the rest of the cluster.
For instance, a poorly written Spark program can accidentally try to bring back many Terabytes of data to the driver machine, causing it to crash. For instance with the take function.
Analytics
Edge nodes are also used for data science work on aggregate data that has been retrieved from the cluster. For example, a data scientist might submit a Spark job from an edge node to transform a 10 TB dataset into a 1 GB aggregated dataset, and then do analytics on the edge node using tools like R and Python.