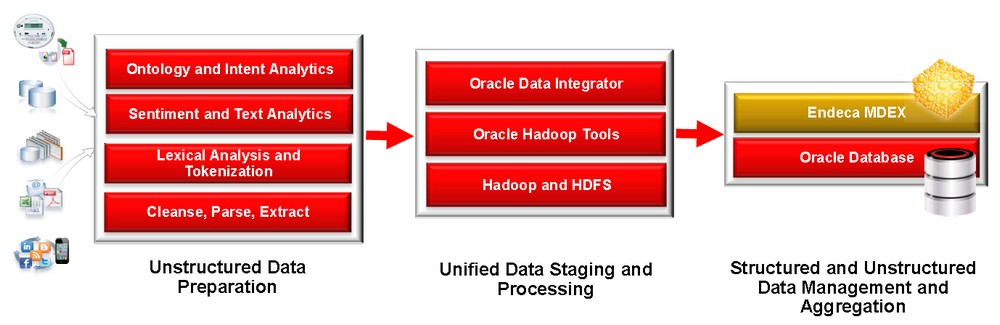
About
Content Enrichment is the process of deriving and determining structure from unstructured content to enhance and augment data. It uses Natural Language Processing (NLP).
Advanced content enrichment of unstructured content can be examined algorithmically to find and extract
- Key Entities (Ex: People, Places, Products)
- Theme. Concepts and entities that are less tangible than “Key Entities”
- Quotations and Document Summaries (Quotes present in content, Summarize content by extracting key message)
- Abstract Concepts (Ex. Process)
- Sentiment (Ex. Content appears to be positive, negative or neutral about a subject)
Basic Content Enrichment can be done by tagging a document based on a search using:
- a “white-list” of terms
- of regular expressions.
Articles Related
Prerequisites
- The Text Enrichment component utilizes the Salience Engine from Lexalytics that you can get from the edelivery platform.
- For Windows Java development, the bin directory (ie C:\Program Files (x86)\Lexalytics\salience\bin) must be in the path in order to load the wrapper file (java_salience.dll) and the engine (SalienceFive.dll).
- Run on Windows and Linux
- .Net, Java, PHP, and python wrappers.
Memory and CPU Foot print
Lexalytics recommends no more than one Salience session per available CPU core because of the CPU-intensive nature of the text analytics processing.
- 200 tweets per second per core
- 4 docs per second per core (4kb or less) or 350 000s doc by day
The base memory footprint for a single Salience session with the Concept Matrix™ is 1006MB, or roughly 1GB.