About
BigQuery is a scanning database, and you’re charged for the amount of data scanned. BigQuery charges based on the amount of data scanned by your queries.
Articles Related
Architecture
With BigQuery, you’re not constrained by the storage capacity or compute resources of a given cluster. Instead, you can load large amounts of data into BigQuery without running out of memory, and execute complex queries without maxing out CPU.
This is possible because BigQuery takes advantage of distributed storage and networking to separate data storage from compute power. Data is distributed across many servers in the Google cloud using their Colossus distributed file system. When you execute a query, the Dremel query engine splits the query into smaller sub-tasks, distributes the sub-tasks to many computers across Google data centers, and then re-assembles them into your results.
Structure
- Fully Qualified Table Name: project_id:dataset.table
Getting Started
Pricing
BigQuery has two pricing options:
- variable - you pay for the data you load into BigQuery, and then pay only for the amount of data you query. BigQuery allows you to setup Cost Controls and Alerts to help control and monitor costs.
- and fixed pricing. Fixed-price plans are geared toward high-volume customers and allow you to rent a fixed amount of compute power.
Structure
Views
BigQuery’s views are logical views, not materialized views, which means that the query that defines the view is re-executed every time the view is queried.
BigQuery’s views are logical views, not materialized views, which means that the query that defines the view is re-executed every time the view is queried. Queries are billed according to the total amount of data in all table fields referenced directly or indirectly by the top-level query.
partitioned-tables
https://cloud.google.com/bigquery/docs/partitioned-tables
To query a full table, you can query like this:
select *
from <project-id>.<source-name>.<collection-name>
- To query a specific partitioned table, you can query like this:
select *
from <project-id>.<source-name>.<collection-name>$20160809
Example
SELECT * EXCEPT (ROW_NUMBER) FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY loaded_at DESC) ROW_NUMBER
FROM project.dataset.table
WHERE _PARTITIONTIME BETWEEN
TIMESTAMP_TRUNC(TIMESTAMP_MICROS(UNIX_MICROS(CURRENT_TIMESTAMP()) - 60 * 60 * 60 * 24 * 1000000), DAY, 'UTC')
AND TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), DAY, 'UTC')
)
WHERE ROW_NUMBER = 1
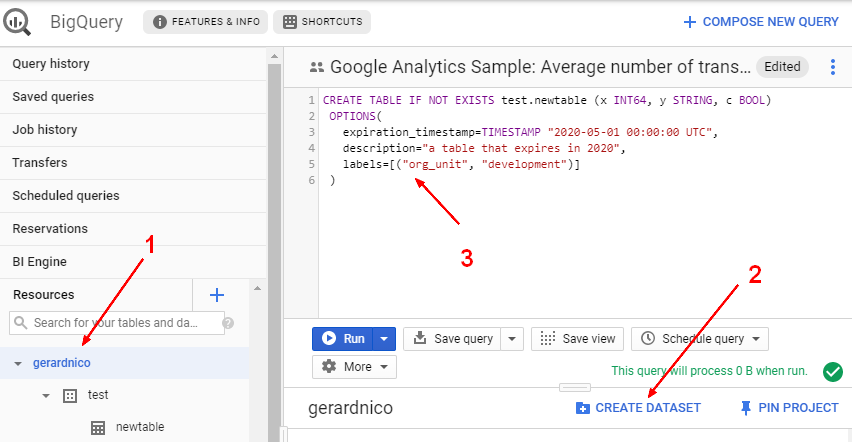
- a table that expires in 2020
CREATE TABLE IF NOT EXISTS mydataset.newtable (x INT64, y STRING, c BOOL)
OPTIONS(
expiration_timestamp=TIMESTAMP "2020-05-01 00:00:00 UTC",
description="a table that expires in 2020",
labels=[("org_unit", "development")]
)