About
UTF-16 is a variant of unicode. It's variable-length encoding: Each code point in a UTF-16 encoding may require either one or two 16-bit code units. The size in memory of a string of length n varies based on the particular code points in the string.
Finding the nth code point of a string is no longer a constant-time operation as in ucs-2: It generally requires searching from the beginning of the string.
Articles Related
Management
How to show character above 16 bit
Unicode can now show characters above 16 bit (to 32 bit), to show this additional characters, code point are concatenated in what's called Unicode - Surrogate pair (UTF-16).
More, see Unicode - Surrogate pair (UTF-16)
Example
Javascript
The charCodeAt() method returns the UTF-16 code unit (an integer between 0 and 65535) at the given index.
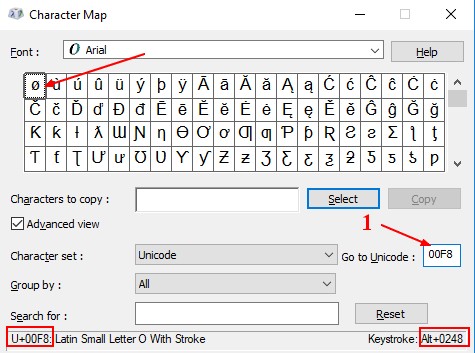
codePointDecimal='ø'.charCodeAt(0)
console.log(codePointDecimal);
codePointHexa=codePointDecimal.toString(16)
console.log(codePointHexa);
If you go to the character map of windows, you can search it (ie with leading zero 00F8 ) and validate that it's the good one.