About
A string is a sequence of bytes that may represent characters. All the characters within a string have a common coding representation. In some cases such as the coding representations may be different at the sending and receiving systems, it may be necessary to convert these characters to a different coding representation.
This process is known as character conversion. Character conversion, when required, is automatic, and when successful, is transparent to the application.

As a result of having many character encoding methods in use (and the need for backward compatibility with archived data), many computer programs have been developed to translate data between encoding schemes. On Firefox 3, for example, see the View/Character Encoding sub-menu (here in Dutch).
Relaxing the code page constraint (or validation) means that this process must not be entirely successful and then you can end up with loss of data during the conversion.
Articles Related
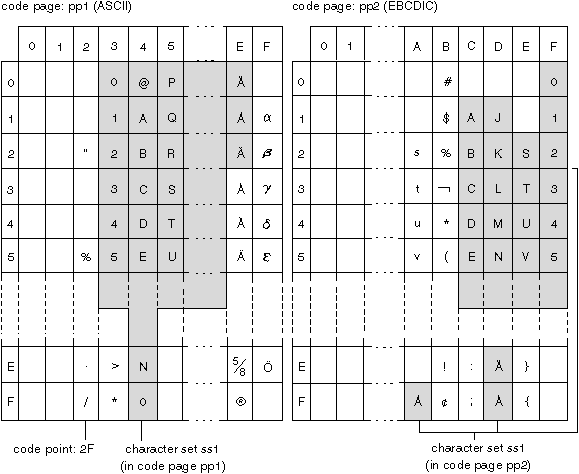
Mapping a Character Set in Different Code Pages
The following figure shows how a typical character set might map to different code points in two different code pages.
Even with the same encoding scheme, there are many different code pages, and the same code point can represent a different character in different code pages.
Furthermore, a byte in a character string does not necessarily represent a character from a single-byte character set (SBCS). Character strings are also used for mixed and bit data. Mixed data is a mixture of single-byte, double-byte, or multi-byte characters. Bit data (columns defined as FOR BIT DATA, or BLOBs, or binary strings) is not associated with any character set.