About
A character is:
- an atomic unit of text (ISO/IEC 10646:2000 Character specification]
- is categorized as a primitive data type
A character is the smallest component of written language that has semantic value; refers to the abstract meaning and/or shape …
Characters will not appear on your screen as intended unless you have the appropriate font (that contains the appropriate glyph)
Character are the basic unit of organization of encoded text.
A character is usually represented as an Unicode code point where an int value from 0 to 65535 represents all Unicode code points, including supplementary code points.
Example
A Character can also be simply a set of characters:
- letters,
- numbers,
- symbols (mathematical),
- ideograms,
- logograms (from non-phonetic writing systems such as kanji),
- etc…
For example, the following character set appears in several code pages:
- 26 non-accented letters A through Z ( A,B,C….X,Y,Z)
- 26 non-accented letters a through z ( a,b,c,…x,y,z)
- digits 0 through 9
- special characters:
- punctuation: . , : ; ? !
- ( ) ' “ / - _ & + % * = < >
Type/Category
- …
Management
Typing
You can type character directly from a keyboard where each key represents a character according to the keyboard layout
Encoding, File Storage
Show
Bash
Problem: Which character is –
Steps:
- The Character Set is UTF8. We got then hexadecimal in UTF8.
echo $LANG
The Hexadecimal in UTF8 of this character is e2 80 93. It corresponds to the unicode character 2013 - EN DASH. See Translation of a UTF-8 Multibyte sequence to Unicode - Example 2. 0a is the end of file.
echo – | hexdump -C
00000000 e2 80 93 0a |....|
00000004
Javascript
The charCodeAt() method returns the UTF-16 code unit (an integer between 0 and 65535) at the given index.
Example with the cldr/utility/character.jsp
'ø'.charCodeAt(0).toString(16);
The below code point reporter is based on the above function and shows for each character of a string its code point.
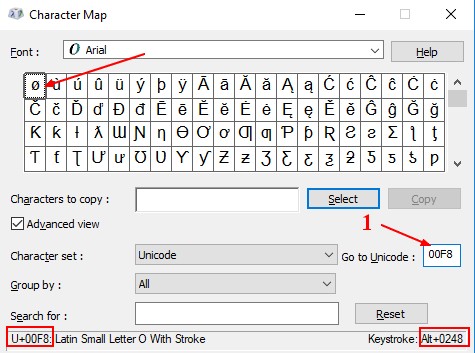
Windows
The character map application of windows where you can search
Java
Character.toChars(int)[0]
For example, Character.isLetter(0x2F81A) returns true because the code point value represents a letter (a CJK ideograph).
Diff
Characters such as an hyphen (-) and a dash are really difficult to separate from each other visually.
In this case, you should transform them as code point to see the difference. See the dedicated page: How to see the difference between two characters (hyphen and dash) ?
Storage
Each character requires: