About
A smoothing spline is a way of fitting splines without having to worry about knots.
They are a little bit more challenging mathematically as others splines and approaches the problem from a completely different point of view.
It's called a smoothing spline because the solution a weird spline that got a knot at every single unique value of the x's. It sounds ridiculous but that's what it is.
Articles Related
Criterion
Criterion for fitting a smooth function g(x) to some data:
<MATH> \begin{array}{rrl} \underset{\displaystyle g \in S}{minimize} & \overbrace{ \underbrace{\sum_{i=1}^{n}(y_i - g(x_i))^2}_{\displaystyle \href{rss}{RSS}} + \underbrace{\lambda \int {g}''(t)^2 dt )}_{\displaystyle \text{Penalty Term}} }^{\displaystyle \text{Criterion}} \\ \end{array} </MATH>
It's a cubic spline because the second derivative is present in the function. If it was a k-th derivative, then it would be a 2k plus first spline
We're searching over all g functions of x. g is unknown.
RSS
The first term is the residual sum of squares (on the left) and tries to make <math>g(x)</math> match the data at each <math>x_i</math>
If we didn't have the second term, we'd just pick any crazy interpolating function that visited every y exactly.
Penalty
Derivatives
The second term adds up all non-linearities in the function.
It will constrains the functions g to be smooth. This complex penalty is the second derivative of the function, squared (to gets rid of the sign), integrated over the whole domain. (Integrate means add them up.)
The second derivatives are going to pick up wiggles of the function, the departures, for example, from linearity.
Lambda
lambda is called the roughness penalty and controls how wiggly the function can be. It modulates how much of the penalty you're imposing. It's then a tuning parameter. lambda is bigger than or equal to 0.
As lambda goes from 0 to infinity, we get a range of functions solutions that are going to go from a linear function to a very wiggly function that goes through the data.
Small
The smaller lambda, the more wiggly the function can be. If lambda is 0, we'll get that interpolating function because we won't pay any price for being wiggly.
Large
On the other hand, as lambda gets really large, if it gets off to infinity, we pay a big price and the function will eventually be forced to be linear because a function that's linear has a second derivative 0.
So the first term would be 0 only if lambda gets to infinity.
Fitted Matrix
The fitted values can be written as a matrix times the observed vector of responses.
<MATH> \hat{g}_\lambda = S_\lambda y </MATH> where:
- <math>\hat{g}_\lambda</math> (g hat indexed by lambda) is a vector containing the fitted values at each of the observed x's.
- <math>y</math> is the observed vector of responses.
- <math>S_\lambda</math> S is an n by m matrix and is determined by the positions of the x's and the particular value of lambda used.
It's a special form called a linear smoother because it's a linear operator times y.
All polynomial regression (splines, …) have a linear operator as the linear regression. All polynomial regression, result in such expressions and it's mathematical properties are attractive for computing (such as see below the degree of freedom
Degree of freedom
The effective degrees of freedom are given by:
<MATH> df_\lambda = \sum_{i=1}^{n}{S_\lambda}_{ii} </MATH>
The degrees of freedom are much less because of the roughness penalty than the natural spline.
The effective degrees of freedom formula doesn't guarantee an integer.
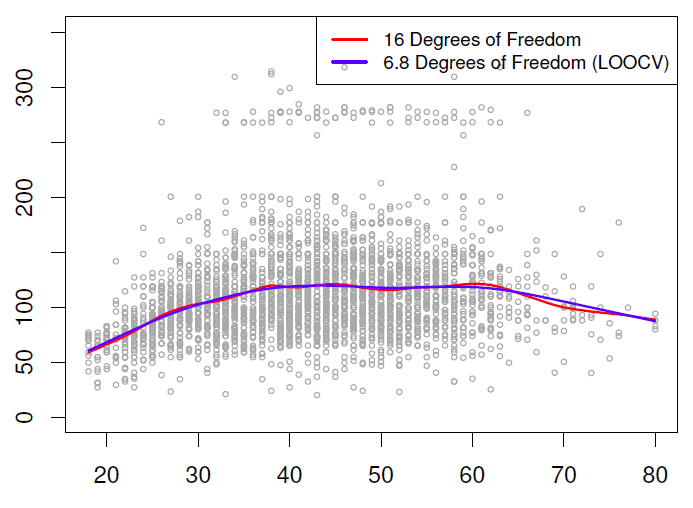
The degrees of freedom for the first model (16) was set manually whereas the second was find by cross-validation.
Cross Validation
You can estimate the smoothing parameter (lambda) by cross-validation.
leave-one-out (LOO)
Leave-one-out cross-validation is quite attractive because it has a really nice expression.
The leave-one-out (LOO) cross-validated error is given by
<MATH> RSS_{cv}(\lambda) = \sum^n_{i=1} (y_i - \hat{g}_\lambda^{-i}(x_i))^2 = \sum^n_{i=1} \left [\ \frac{y_i - \hat{g}_\lambda(x_i)}{1-\{S_\lambda\}_{ii}} \right ]^2 </MATH>
This is the sum of cross-validated residuals.
- To compute the first whole expression, we would have to leave out each point and refit the function each time.
- But It turns out you can just fit a smoothing spline to the original data and divide each of the residuals by 1 minus the corresponding diagonal element of that smoother matrix (the second expression). It's sort of like a magic formula.
You calculate it for a range of values of lambda and pick the value that minimizes it.