About
Data rules are rule that can have various designations such as:
- business rules (in the data modeling),
- data test,
- quality screen.
They follow the same concept than the rules from an event driven architecture.
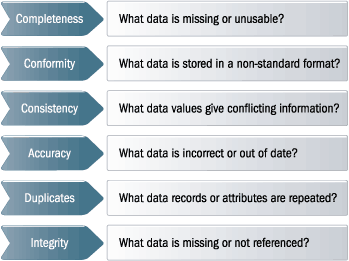
Data quality rules fall into two categories to help on the data cleansing process:
- data detecting rules which must design the business rules
- data correction rules which take place in the data correction process
Articles Related
Validations rules
One set of rules, validations, simply asserts what must be true about the data, and is used as a means of validating that data conforms to our expectations. Both data transformation and data profiling products will allow the end client to define validation rules that can be tested against a large set of data instances. For example, having determined through profiling that the values within a specific column should fall within a range of 20-100, one can specify a rule asserting that “all values must be greater than or equal to 20, and less than or equal to 100.” The next time data is streamed through the data quality tool, the rule can be applied to verify that each of the values falls within the specified range, and tracks the number of times the value does not fall within that range.
Data Rule Type
The following data rules may be discover or classify through three type of data profiling analysis.
| Data Rule Type | Data profiling Analysis | Description | Example |
|---|---|---|---|
| Domain List | Attribute Analysis | A domain list rule defines a list of values that an attribute is allowed to have. | The Gender attribute can have 'M' or 'F'. |
| Domain Pattern List | Attribute Analysis | A domain pattern list rule defines a list of patterns that an attribute is allowed to conform to. The patterns are defined in the regular expression syntax. | An example pattern for a telephone number is as follows: (^[[::space]]*[0-9]{ 3 }[[::punct|:space:]]?[0-9]{ 4 }[[::space]]*$) |
| Domain Range | Attribute Analysis | A domain range rule defines a range of values that an attribute is allowed to have. | The value of the salary attribute can be between 100 and 10000. |
| Common Format / Pattern | Attribute Analysis | A common format rule defines a known common format that an attribute is allowed to conform to. | This rule type has many subtypes: Telephone Number, IP Address, SSN, URL, E-mail Address. |
| No Nulls | Attribute Analysis | A no nulls rule specifies that the attribute cannot have null values | The department_id attribute for an employee in the Employees table cannot be null. |
| Functional Dependency | Functional Dependency | A functional dependency defines that the data in the data object may be normalized or derived | |
| Unique Key | Attribute Analysis | A unique key data rule defines whether an attribute or group of attributes are unique in the given data object. | The name of a department should be unique. |
| Referential | Referential Analysis | A referential data rule defines the type of a relationship (1:x) a value must have to another value. | The department_id attribute of the Departments table should have a 1:n relationship with the department_id attribute of the Employees table. |
| Name and address | Functional Dependency | A name and address data rule evaluate a group of attributes as a name or address | |
| Custom | - | A custom data rule applies a SQL expression that you specify to its input parameters. | VALID_DATE with two input parameters, START_DATE and END_DATE. A valid expression for this rule is: “THIS”.“END_DATE” > “THIS”.“START_DATE |
Cleansing or correction rules
The second set of rules, cleansing or correction rules, identifies a violation of some expectation and a way to modify the data to then meet the business needs.
You will find more details here : Data Quality - Data Correction