About
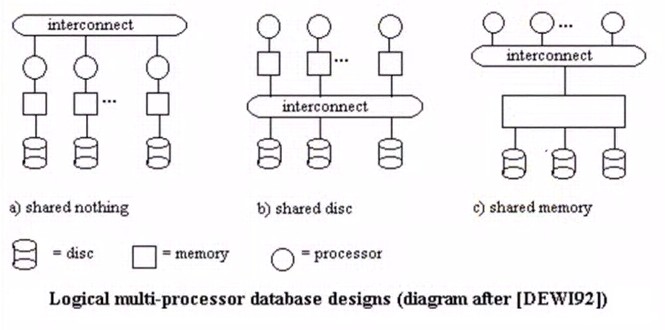
Traditionally, two approaches have been used for the implementation of parallel execution in database systems.
The main differentiation is whether or not the physical data layout is used as a base – and static pre-requisite – for dividing, thus parallelizing, the work.
These fundamental approaches are known as:
- shared everything architecture
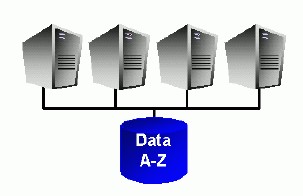
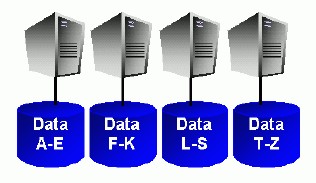
- and shared nothing architecture (related to Data Partition - Sharding (Horizontal Partitioning on many server)
Articles Related
Shared Nothing
Shared Nothing the machine are only connected by the network. The “shared nothing” architecture shares network bandwidth because it must transfer data from machines doing the Map tasks to machine doing the Reduce tasks over the network.
In a shared nothing system CPU cores are solely responsible for individual data sets and the only way to access a specific piece of data you have to use the CPU core that owns this subset of data, such systems are are also commonly known as MPP (Massively Parallel Processing) systems. In order to achieve a good workload distribution MPP systems have to use a hash algorithm to distribute (partition) data evenly across available CPU cores.
As a result MPP systems introduce mandatory, fixed parallelism in their systems in order to perform operations that involve table scans, the fixed parallelism completely relies on a fixed static data partitioning at database or object creation time. Most non-Oracle data warehouse systems are MPP systems.
A “shared nothing” architecture means that each computer system has its own private memory and private disk.
This architecture is followed by essentially all high performance, scalable, DBMSs, including Teradata, Netezza, Greenplum, Paraccel, DB2 and Vertica. It is also used by most of the high-end e-commerce platforms, inclusing Amazon, Akamai, Yahoo, Google, and Facebook.
Shared everything
Shared everything is also known as shared memory or shared everything.
Oracle RAC does not run on a shared nothing system. It was built many years ago to run on a “shared disk” architecture.
In this world, a computer system has private memory but shares a disk system with other computer systems. Such a “disk cluster” was popularized in the 1990’s by Sun and HP, among others In the 2000’s this architecture has been replaced by “grid computing”, which uses shared nothing.
Shared disk has well-known scalability problems, when applied to DBMSs. These result from the requirement that each system have its own lock table and buffer pool, which must be synchronized with their peers. This synchronization is painful and has serious performance problems, which limit the scalability of shared disk implementations. In fact, the largest Oracle RAC configuration I am aware if is 6 systems. In contrast shared nothing DBMSs, such as Vertica, are routinely run on 50-100 nodes.
But thanks to the shared everything architecture the Database does not require any pre-defined data partitioning to enable parallelism. The database can parallelize almost every operation, independent of the underlying data distribution. If, however, the data has been pre-partitioned (using Partitioning), the database can use the same optimizations and algorithms shared nothing vendors claim.
Oracle Database uses a shared everything architecture, which from a storage perspective means that any CPU core in a configuration can access any piece of data; this is the most fundamental architectural difference between Oracle and all other major database products on the market.
Summary
??? In summary, shared nothing scales much better than shared disk. Hence, it is the superior architecture ???