
About
Linear regression is a regression method (ie mathematical technique for predicting numeric outcome) based on the resolution of linear equation.
This is a classical statistical method dating back more than 2 centuries (from 1805).
The linear model is an important example of a parametric model.
Linear regression is very extensible and can be used to capture non-linear effects.
This is very simple model which means it can be interpreted.
There's, typically, a small number of coefficients. If we have a small number of features that are important,, it predicts future data quite well in a lot of cases, despite it's simplicity.
Articles Related
Problem definition
You have a cloud of data points in (2|n) dimensions and are looking for the best straight (line|hyperline) fit.
You might have more than 2 dimensions. It's a standard matrix problem.
Assumption
- Linear Regression assumes that the dependence of the target <math>Y</math> on the predictors <math>X_1, ..., X_p</math> is linear. Even if true regression functions are never linear.
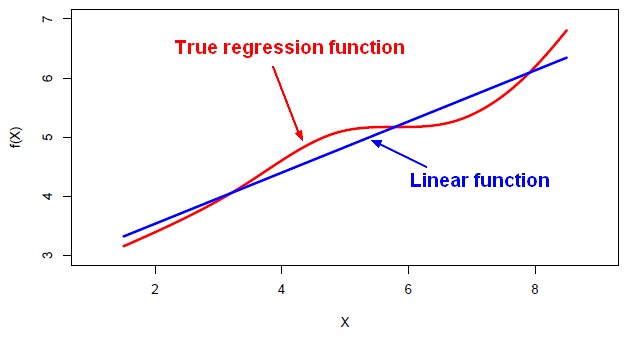
Model
It produces a model that is a linear function (i.e., a weighted sum) of the input attributes.
There are non-linear methods that build trees of linear models.

In two dimensions, it's a line, in three a plane, in N, a hyperplane.
Formula:
<math>Y = B_0 + B_1.X_1 + B_2.X_2+ \dots +B_p.X_p</math>
where:
- the B values are weight (known also as regression coefficient or parameters).
- the X values are the value of the predictors variable.
Linear Regression works naturally with numeric classes (not with nominal ones) because the predictors are multiplied by weights but can be used for classification as well.
Procedure
- Calculate weights (B) from training data. Large correlation is good, and the value cannot be greater than 1.
Classification
Two‐class problem
Linear regression can be used for binary classification as well:
- Calculate a linear function using regression
- and then apply a threshold to decide whether it's 0 or 1 (two-valued nominal classes).
Steps:
- On the training dataset: convert the class to binary attributes (0 and 1)
- Use the regression output and the nominal class as an input for One_Rule in order to define a threshold
- Use this threshold for predicting class 0 or 1
Multi-class problem
For more class labels than 2, the following methods can be used:
- multi-response linear regression
- pairwise linear regression
Steps:
- Training: perform a regression for each class. N regression for a problem where there are n different classes. Set output to 1 for training instances that belong to the class, 0 for instances that don’t
- Prediction:
- choose the class with the largest output
- or use “pairwise linear regression”, which performs a regression for every pair of classes
Example for multi-response linear regression:
For a three class problem, we create three prediction model where the target is one class and zero for the others.
If the actual and predicted outputs for the third instance are:
| Instance Id | Model | Numeric Class | Prediction |
|---|---|---|---|
| 3 | Blue | 0 | 0.359 |
| 3 | Green | 1 | 0.322 |
| 3 | Red | 0 | 0.32 |
the predicted class is Blue because the first model predicts the largest output.
The actual class of the instance 3 is Green because the numeric class is a 1 in the second model
Improvement
By replacing ordinary least squares fitting with some alternative fitting procedures, simple linear model can be improved in terms of:
- Prediction Accuracy: especially when p > n, to control the variance.
Performance
M5P performs quite a lot better than Linear Regression.
Implementation
Weka
Weka has a supervised attribute filter (not the “unsupervised” one) called NominalToBinary that converts a nominal attribute into the same set of binary attributes used by LinearRegression and M5P.
To show the original instance numbers alongside the predictions, use the AddID unsupervised attribute filter, and the “Output additional attributes” option from the Classifier panel “More options …” menu. Be sure to use the attribute *index* (e.g., 1) rather than the attribute *name* (e.g., ID).