
About
Bias in stats
Bias is a systematic error in sampling or measurement.
Systematic measurement error represents bias.
It has an effect on the entire distribution (It shift it right or left).
The bias is how far off on the average the model is from the truth.
More the model is complex, more the bias will decrease.
See also: Statistics - Bias-variance trade-off (between overfitting and underfitting)
Articles Related
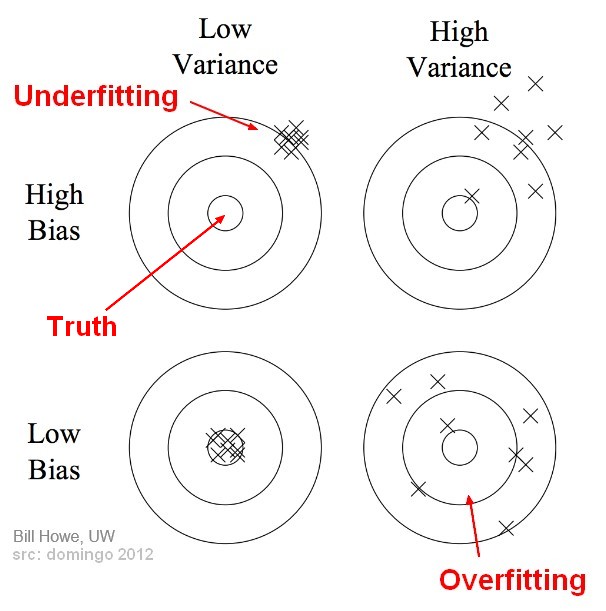
Example
- Measurement Bias: An instrument that will always measure with the same difference.
- Sampling Bias: If we made our sample in an area where a large number of person tend to congregate (such as a city), it may lead to population estimate that is too high.